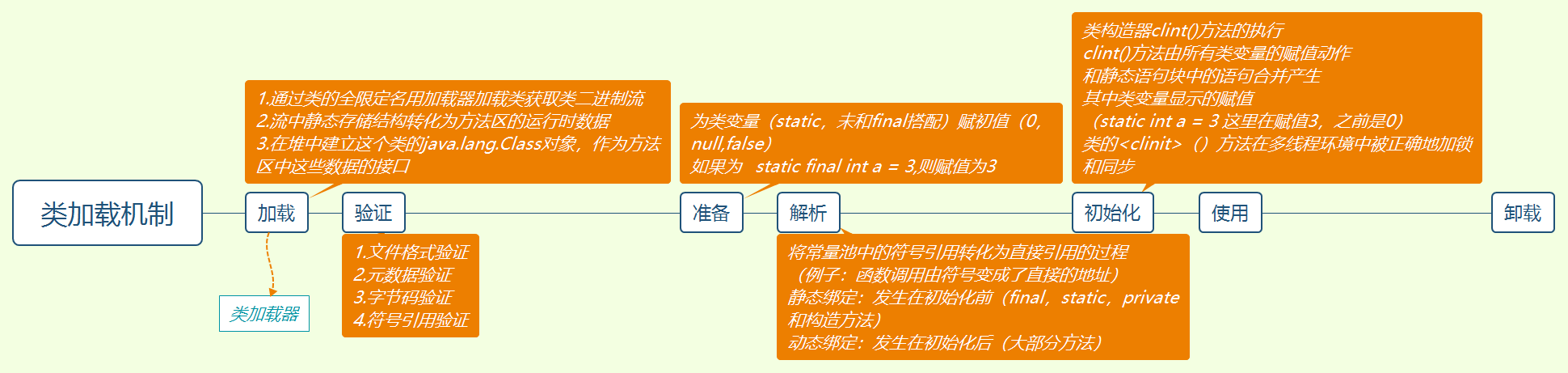
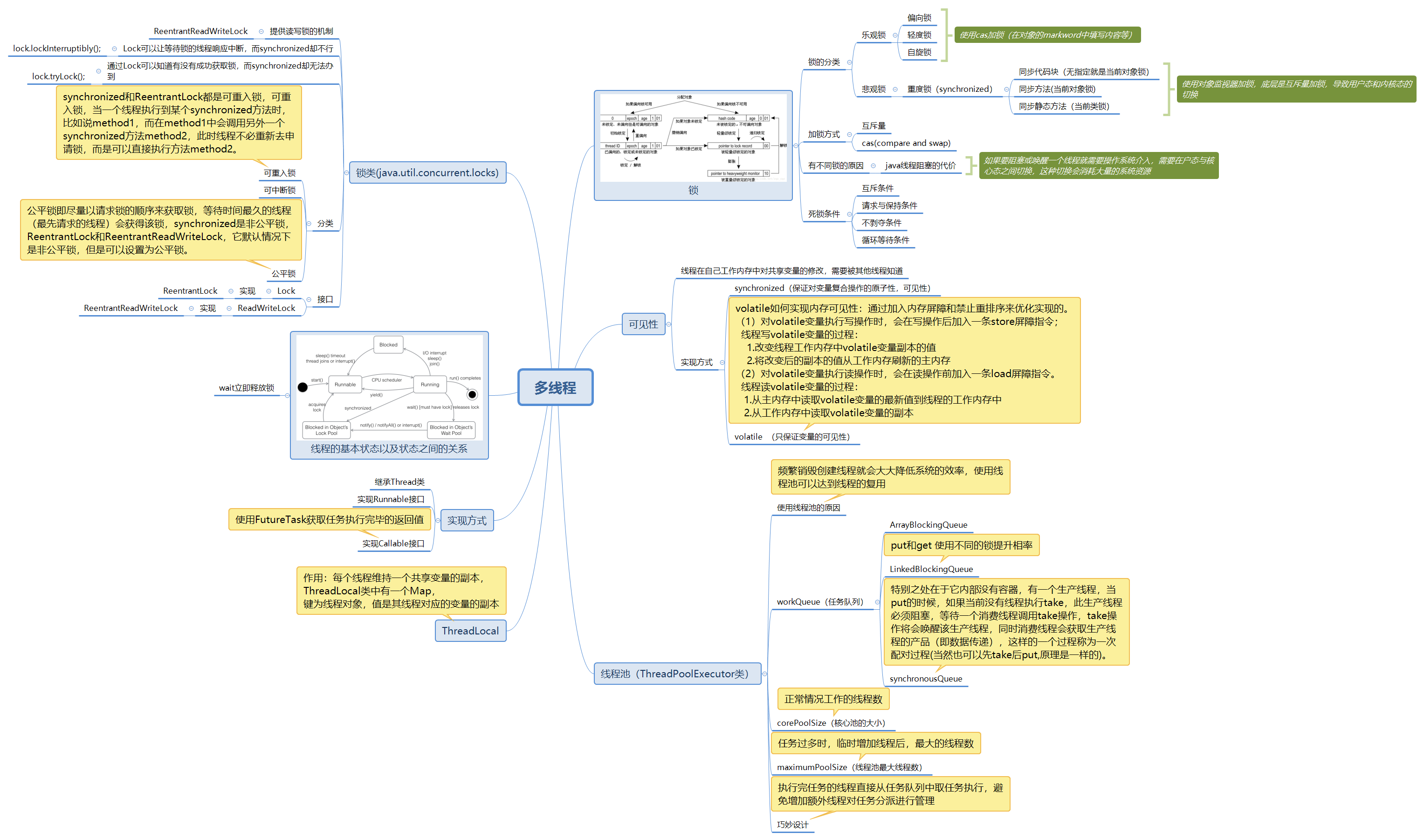
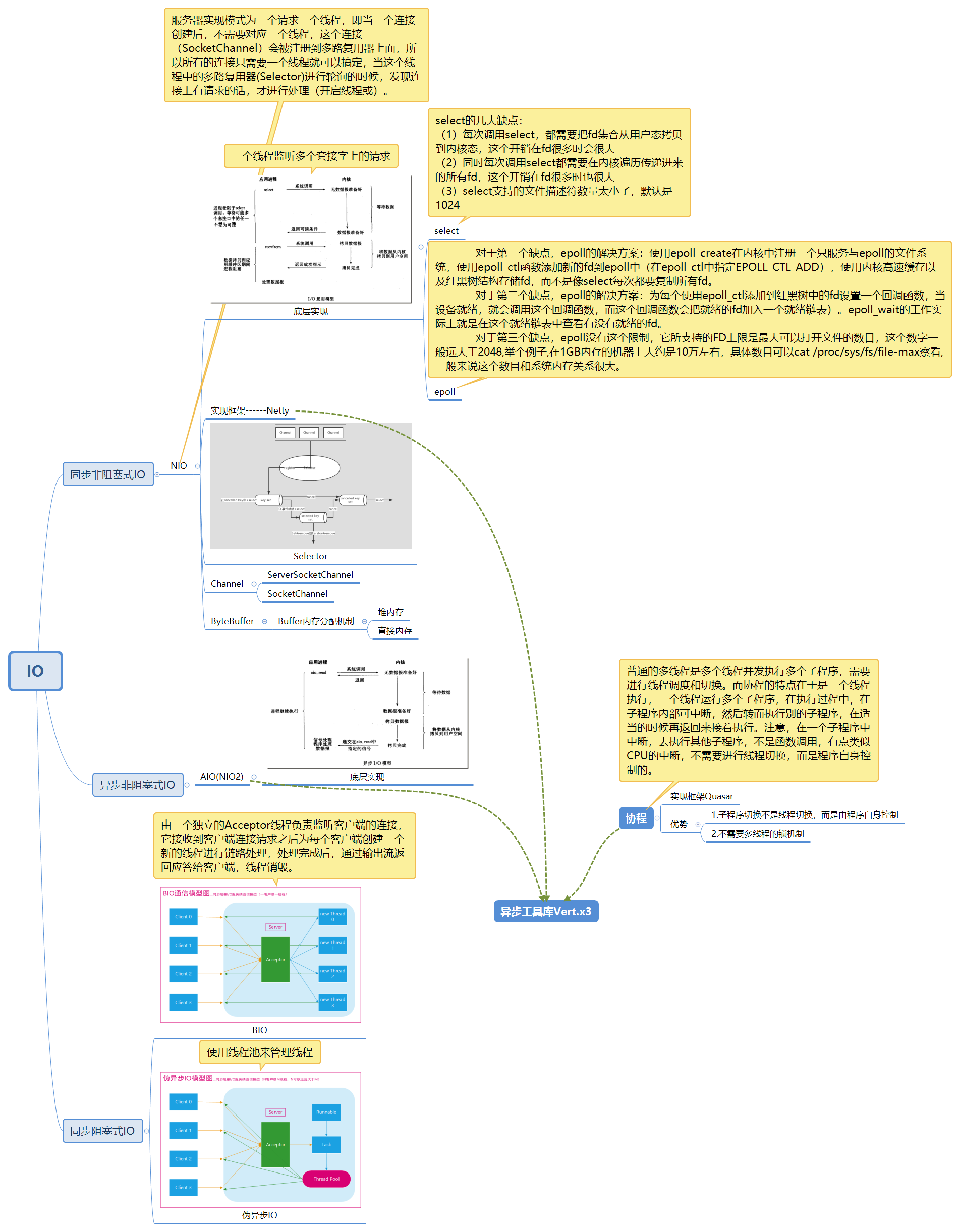
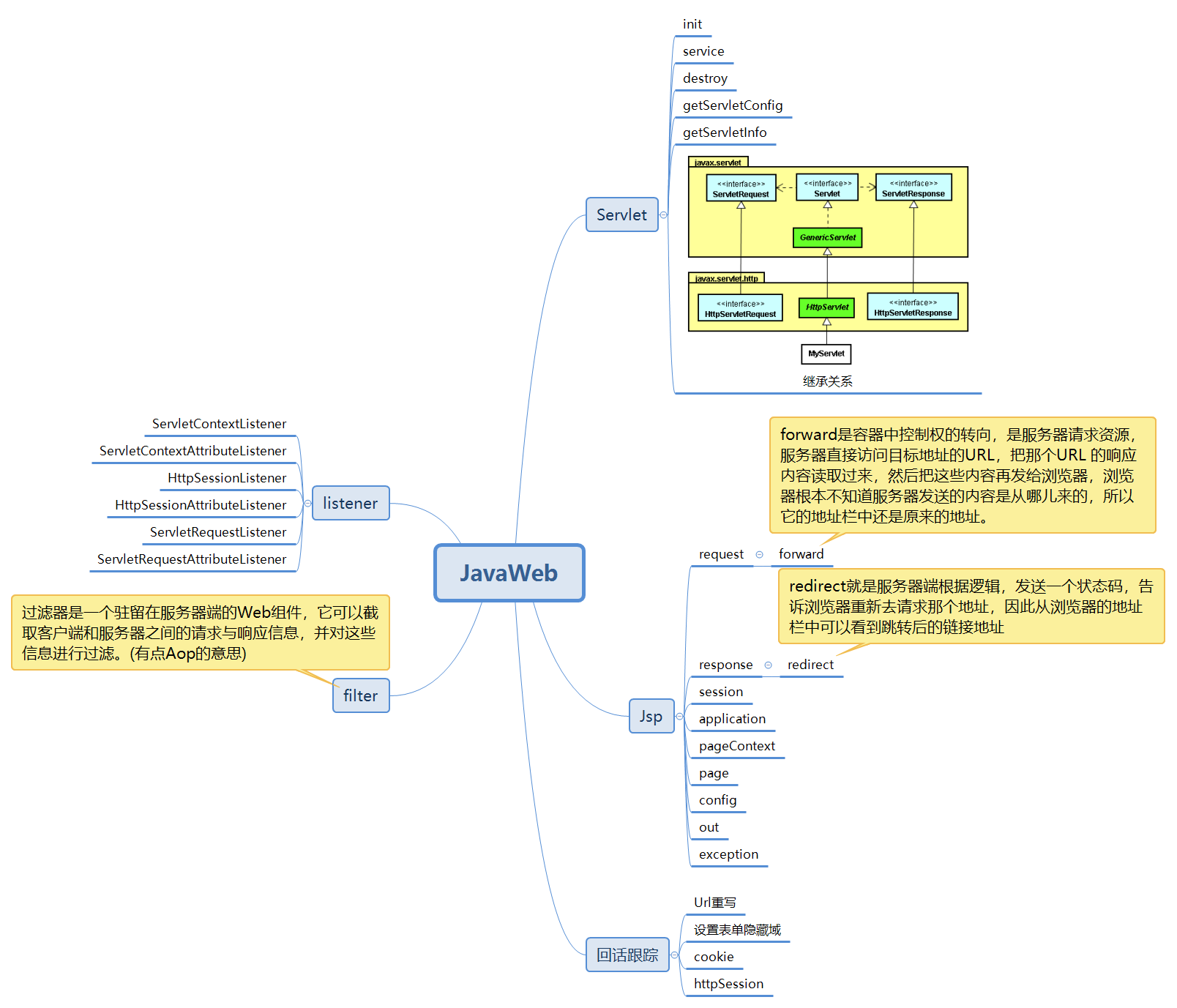
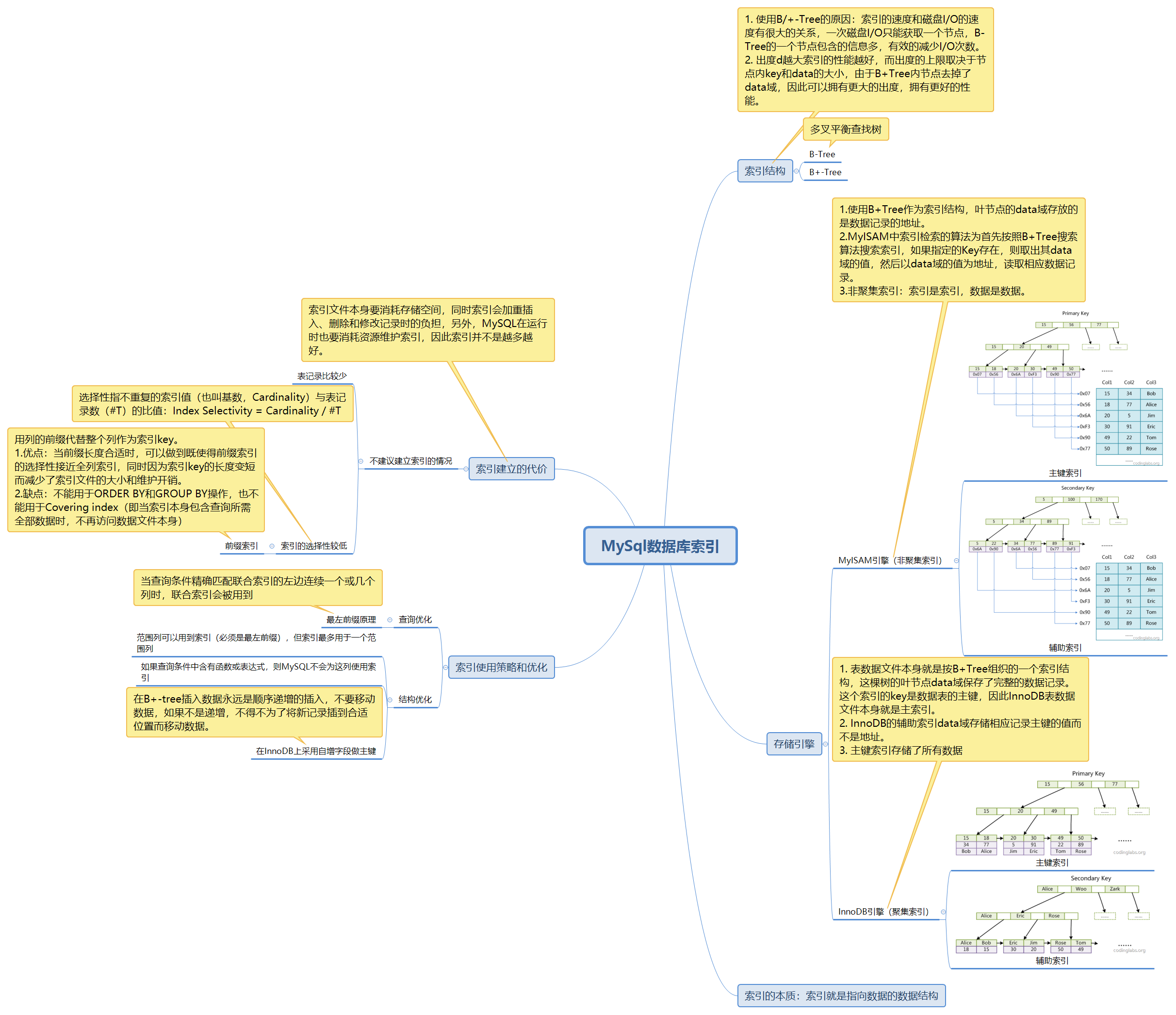
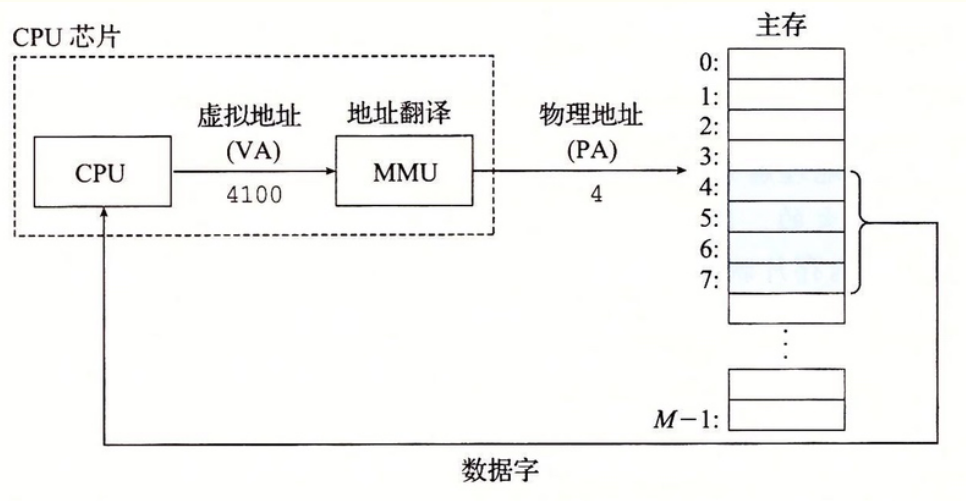
pblk_structure
code list
1 | core.c //lightnvm层。与用户库不一样,主要是使用其bio和request的支持 |
块组织
lun和line的关系
lun 0 lun 1 lun 2 lun 3 [blk 0] [blk 0] [blk 0] [blk 0] line 0 [blk 1] [blk 1] [blk 1] [blk 1] line 1 [ ... ] [ ... ] [ ... ] [ ... ] ... [blk n] [blk n] [blk n] [blk n] line n
pblk structure
- pblk.h
1
2
3
4
5
6
7
8
9
10
11struct pblk {
struct pblk_lun *luns; //LUN
struct pblk_line *lines; //LINE
struct pblk_line_mgmt l_mg; //用于管理pblk_line
struct pblk_line_meta lm; //line的元数据,主要是维护各个bitmap结构
struct pblk_rb rwb; //ring buffer的缓存
struct task_struct *writer_ts; //写线程
unsigned char *trans_map; //l2p : logical address to physical address map 逻辑地址到物理地址的映射map
struct pblk_gc gc; GC
//.. 其他的就先省略了
};
pblk-init
pblk-init.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68pblk_init(...)
{
pblk = kzalloc(sizeof(struct pblk), GFP_KERNEL);
ret = pblk_luns_init(pblk, dev->luns); //初始化pblk->luns的物理地址bppa,并对lun中坏块检查
ret = pblk_lines_init(pblk); //初始化line管理者pblk->l_mg(主要是初始化坏块表和各个链表,
//链表包括free_list(读写逻辑的line管理)和gc_list
//(gc逻辑的line管理 )),
//初始化lines元数据pblk->lm(主要是初始化各个bimap),
//同时构建一个个lines中的line结构,并把line添加在free_list中
ret = pblk_core_init(pblk); //创建几个经常使用的struct的slab内核缓存区,
//并创建相应的mempool,管理内核缓存,
//并创建close工作队列和bb工作队列。
ret = pblk_l2p_init(pblk); //初始化l2p map(逻辑地址到物理地址映射表),使用的是一个trans_map
//维护两者的关系
ret = pblk_lines_configure(pblk, flags); //conf of lines
ret = pblk_writer_init(pblk); //设置写操作内核定时器,创建写操作内核线程
ret = pblk_gc_init(pblk); //创建GC内核线程,GC写操作内核线程,GC读操作内核线程,设置GC操作
//内核定时器,创建两个GC操作的工作队列,初始化gc链表
wake_up_process(pblk->writer_ts); //唤醒写线程
return pblk;
}
struct pblk_line {
struct pblk *pblk;
unsigned int id; /* Line number corresponds to the
* block line
*/
unsigned int seq_nr; /* Unique line sequence number */
int state; /* PBLK_LINESTATE_X */
int type; /* PBLK_LINETYPE_X */
int gc_group; /* PBLK_LINEGC_X */
struct list_head list; /* Free, GC lists */
unsigned long *lun_bitmap; /* Bitmap for LUNs mapped in line */
struct pblk_smeta *smeta; /* Start metadata */
struct pblk_emeta *emeta; /* End medatada */
int meta_line; /* Metadata line id */
int meta_distance; /* Distance between data and metadata */
u64 smeta_ssec; /* Sector where smeta starts */
u64 emeta_ssec; /* Sector where emeta starts */
unsigned int sec_in_line; /* Number of usable secs in line */
atomic_t blk_in_line; /* Number of good blocks in line */
unsigned long *blk_bitmap; /* Bitmap for valid/invalid blocks */
unsigned long *erase_bitmap; /* Bitmap for erased blocks */
unsigned long *map_bitmap; /* Bitmap for mapped sectors in line */
unsigned long *invalid_bitmap; /* Bitmap for invalid sectors in line */
atomic_t left_eblks; /* Blocks left for erasing */
atomic_t left_seblks; /* Blocks left for sync erasing */
int left_msecs; /* Sectors left for mapping */
unsigned int cur_sec; /* Sector map pointer */
unsigned int nr_valid_lbas; /* Number of valid lbas in line */
__le32 *vsc; /* Valid sector count in line */
struct kref ref; /* Write buffer L2P references */
spinlock_t lock; /* Necessary for invalid_bitmap only */
};由pblk_init调用的写线程
pblk-write.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48int pblk_write_ts(void *data)
static int pblk_submit_write(struct pblk *pblk)
//从ring buffer缓存中读取数据到bio
unsigned int pblk_rb_read_to_bio(struct pblk_rb *rb, struct nvm_rq *rqd,struct bio *bio, unsigned int pos,
unsigned int nr_entries, unsigned int count)
//提交nvm_rq到底层的lightnvm层
static int pblk_submit_io_set(struct pblk *pblk, struct nvm_rq *rqd)
//ring_buffer数据结构
struct pblk_rb {
struct pblk_rb_entry *entries; /* Ring buffer entries */
unsigned int mem; /* Write offset - points to next
* writable entry in memory
*/
unsigned int subm; /* Read offset - points to last entry
* that has been submitted to the media
* to be persisted
*/
unsigned int sync; /* Synced - backpointer that signals
* the last submitted entry that has
* been successfully persisted to media
*/
unsigned int sync_point; /* Sync point - last entry that must be
* flushed to the media. Used with
* REQ_FLUSH and REQ_FUA
*/
unsigned int l2p_update; /* l2p update point - next entry for
* which l2p mapping will be updated to
* contain a device ppa address (instead
* of a cacheline
*/
unsigned int nr_entries; /* Number of entries in write buffer -
* must be a power of two
*/
unsigned int seg_size; /* Size of the data segments being
* stored on each entry. Typically this
* will be 4KB
*/
struct list_head pages; /* List of data pages */
spinlock_t w_lock; /* Write lock */
spinlock_t s_lock; /* Sync lock */
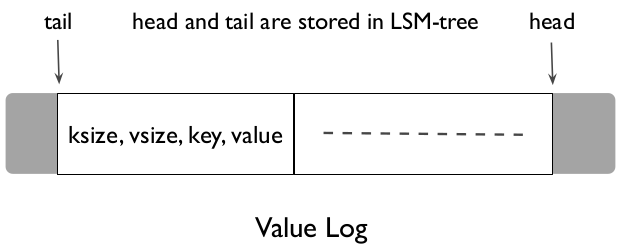
};//ring buffer 就是一个双向page的链表- 从ring buffer缓存中读取数据到bio
- 将bio组织成nvm_rq
- 提交nvm_rq到底层的lightnvm层
从顶层发下来的写请求应该是直接调用了pblk_write_to_cache(…)
这里的写线程只负责把cache中的数据下放到设备
GC
pblk-gc.c
gc初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14int pblk_gc_init(struct pblk *pblk)
{ struct pblk_gc *gc = &pblk->gc;
//创建内核gc线程
gc->gc_ts = kthread_create(pblk_gc_ts, pblk, "pblk-gc-ts");
//创建内核gc写线程
gc->gc_writer_ts = kthread_create(pblk_gc_writer_ts, pblk, "pblk-gc-writer-ts");
//创建内核gc读线程
gc->gc_reader_ts = kthread_create(pblk_gc_reader_ts, pblk, "pblk-gc-reader-ts");
//设置内核定时器
setup_timer(&gc->gc_timer, pblk_gc_timer, (unsigned long)pblk);
mod_timer(&gc->gc_timer, jiffies + msecs_to_jiffies(GC_TIME_MSECS));
//内核定时器唤醒gc线程和gc的读线程和写线程
}gc线程: 检查line的状态(是否写满、是否有脏数据等等),处理全是无效数据的line,把需要搬有效数据的line放到pblk_gc结构体的r_list中
(pblk_gc_ts -> pblk_gc_run)
gc读线程: 根据pblk_gc结构体中的r_list对line进行读取,把读到的有效数据存入w_list
(pblk_gc_reader_ts ->pblk_gc_read ->pblk_gc_line)
gc写线程: 将w_list的内容写入cache(调用gc用来写cache的函数)也就是写入ring buffer,并数据的逻辑地址指向ring buffer中的某个cacheline中
(pblk_gc_writer_ts ->pblk_gc_write -> pblk_write_gc_to_cache -> pblk_rb_write_entry_gc-> pblk_update_map_gc)
写流程
pblk-cache.c
1
2
3
4
5
6
7int pblk_write_to_cache(...)
{
sector_t lba = pblk_get_lba(bio); //从bio结构体获取逻辑地址
pblk_ppa_set_empty(&w_ctx.ppa); //置ppa为空,也就是还没有分配物理地址
pblk_rb_write_entry_user(..) //pblk-rb.c 写入到ring buffer
pblk_write_should_kick(pblk); //唤醒pblk写线程(读cache,写入设备)
}pblk-rb.c:304
1
2
3
4
5
6
7void pblk_rb_write_entry_user(...)
{
__pblk_rb_write_entry(rb, data, w_ctx, entry); //memcpy 写入到ring buffer缓存
pblk_update_map_cache(pblk, w_ctx.lba, entry->cacheline); //更新l2p表
//此时当前逻辑地址对应的物理地址是一个指向cache的标记,即entry->cacheline
//对当前逻辑地址的读操作会直接从cache中进行
}pblk-write.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14static int pblk_submit_write(struct pblk *pblk)
{
pblk_rb_read_to_bio(...) //从ring buffer缓存中读取到bio
pblk_submit_io_set(...) //提交bio
}
static int pblk_submit_io_set(struct pblk *pblk, struct nvm_rq *rqd)
{
pblk_setup_w_rq(pblk, rqd, c_ctx, &erase_ppa); //创建request
//调用pblk_map_rq()来管理l2p表
//pblk_map_rq()调用了pblk_map_page_data()
//分配物理地址ppa并对其加锁(信号量)
pblk_submit_io(pblk, rqd); //提交request到nvm层 in pblk-core.c
}pblk-map.c
1
2
3
4
5
6
7
8
9
10
11
12
13pblk_map_page_data(...)
{
struct pblk_line *line = pblk_line_get_data(pblk); //获取pblk的data line(当前用来写入数据的line)
paddr = pblk_alloc_page(pblk, line, nr_secs); //从当前line中分配一个页
ppa_list[i] = addr_to_gen_ppa(pblk, paddr, line->id); //循环获取ppa地址
w_ctx->ppa = ppa_list[i]; //将ppa赋值给w_ctx(每个w_ctx是一个bio的写请求的上下文)
//这一步才真正的给逻辑地址分配了物理地址
//但是还找不到具体如何update了l2p表。。。
pblk_down_rq(pblk, ppa_list, nr_secs, lun_bitmap); 加锁 pblk-core.c
}