Log-Structured Merge Tree(LSM-Tree)的特点:
维护顺序模式的写操作(更新操作也是写),而在B-Tree中一个更新操作可能会带来很多随机写。
LSM-Tree存在的问题:
LSM-Tree在HDD上表现的很好,因为HDD的随机I/O比顺序I/O慢得多,使用额外的顺序读写(Merge(compact),Sort)减少随机的读写可以带来很大的性能提高。
- 但是SSD的随机I/O和顺序I/O的差异不像HDD那么大。
- SSD写放大问题会在LSM-Tree增加的额外的写上更加严重,这样会影响SSD的命。
- LSM-Tree没有很好的利用SSD内部的并行。
- 写放大:两个level之间的compaction造成,合并一个L(i-1)的文件,可能最差10个L(i)的文件,排序后,再重新写下去。
- 读放大:查询一个key,可能要查询多个文件,并且还需要读取元数据(index block,boolom fiter block)等。
WiscKey特点:
- WiscKeys 从键值中分离键,只保留 LSM-tree 中的键,并将值保存在单独的日志文件中。
- 为了处理未分类值(在范围查询期间需要随机访问),WiscKey 使用 SSD 设备的并行随机读取特性。
- WiscKe 利用独特的崩溃一致性和垃圾收集技术来高效地管理值日志。
- WiscKey 通过在不牺牲一致性的情况下移除 LSM-tree 日志来优化性能,从而减少小写入造成的系统调用开销。
WiscKey可能的问题:
- 如果小的Value按顺序编写,并且按顺序查询一个大数据集,则 WiscKey 执行比 LevelDB 差。
- 需要对Vlog(value值的日志文件进行垃圾回收)!
- 用于key和value分开,范围查询(range)由原来的顺序读,变成了随机读(读取vlog中的value是随机的)
- Wisckey的空间放大比levelDB的严重,(实际存储的数据比逻辑的多)重点!
- 在范围查询中,value小的情况,WiscKey不是很好,(value不是排序的。。。)重点!
WiscKey的问题的解决方式
- 对于问题2,采用一种lightweight的垃圾回收机制,改变了Vlog存储的格式,在head插入新的value,在tail开始选出一定大小的chunk,进行垃圾回收。
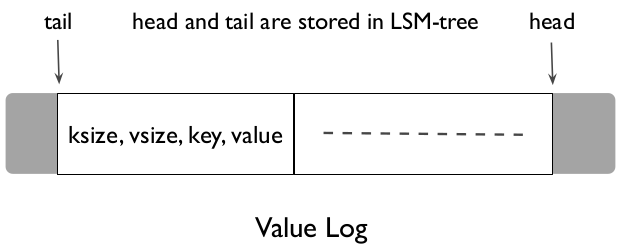
- 对于问题3,采用预取key的方式,当出现连续的kv查询时,判断为范围查询,这时候就预取多个key_valueAddress,开多个线程通过预取出来的valueAddress获取value(利用设备的并行性)
WiscKey的添加的新特性
- 使用一个用户态的vlog buffer,处理小写(每个value_size都小)多次使用系统调用write所带来的开销。
- Vlog既用来存储value,又用来crash恢复,移除了Level_DB的wal。
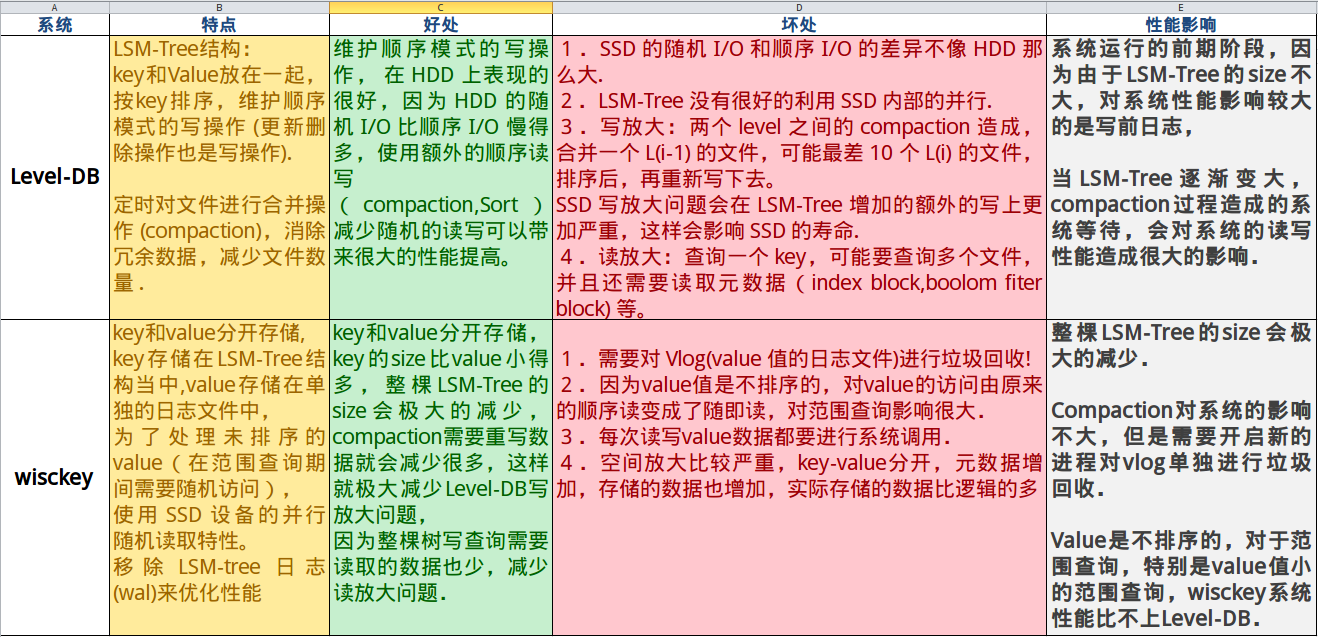
两者存储结构的对比
相关工作
- 对原始 LSM 树键值存储进的优化。
- bLSM 提出了一种新的合并调度器来限制写入延迟,从而保持稳定的写入吞吐量,并且还使用 bloom 过滤器来提高性能。
- VT-tree 通过使用间接层来避免在压缩期间排序任何先前排序的键值对。 WiscKey 直接将键值与键分离,显着减少了写入放大,无论工作负载中的密钥分配如何。
- LOCS 将内部闪存通道暴露给 LSM 树键值存储区,该存储区可以利用丰富的并行性来实现更高效的压缩。
- Atlas是基于ARM处理器和擦除编码的分布式键值存储,并将密钥和值存储在不同的硬盘上。 WiscKey 是独立的键值存储,其中键和值之间的分隔高度优化,以便SSD设备实现明显的性能提升。
- LSM-trie 使用一个 trie结构来组织密钥,并提出基于该 trie 的更高效的压缩; 然而,这种设计牺牲了 LSM-tree 的功能,例如对范围查询的有效支持。
- RocksDB 由于其设计与 LevelDB 基本相似,仍然表现出很高的写入放大率; RocksDB 的优化与 WiscKey 的设计是正交的。
- Walnut 是一个混合对象存储,它将小对象存储在 LSM 树中,并将大对象直接写入文件系统。
- IndexFS 将其元数据存储在 LSM 树中,并使用列样式模式来加速插入的吞吐量。
- Purity 还通过对索引进行排序并按时间顺序存储元组,将其索引与数据元组分开。
7,8,9三个系统都使用与 WiscKey 相似的技术。